豆包UltraMem,打破AI算力天花板的“全新稀疏模型架构”黑科技

- 2025-02-13
- 147 阅读
当AI对话卡成“人工智障”,是谁在背后偷偷升级算力?
你是否遇到过这样的场景:向AI提问时,它突然卡顿,屏幕上缓缓飘出“服务器繁忙”的提示?这背后不仅是用户量的暴增,更是AI模型“算力天花板”的残酷现实。传统的Transformer模型每提升10倍性能,算力需求就要增长100倍;混合专家系统(MoE)试图用“专家分工”破局,却仍被内存访问拖慢速度——直到UltraMem这项黑科技横空出世。
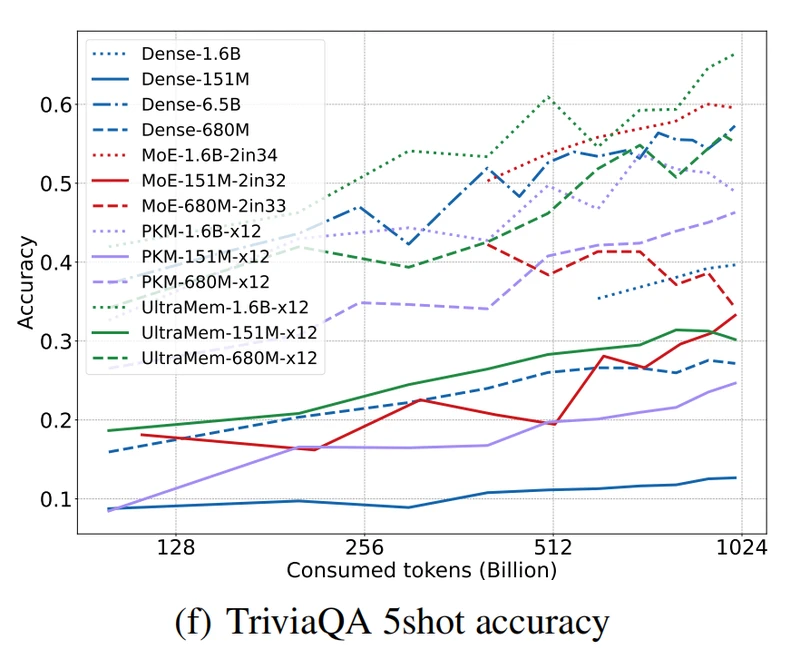
字节跳动Seed-Foundation-Model团队的最新论文显示,UltraMem在1.6亿参数规模的测试中,推理速度比MoE快6倍,性能却更优。它究竟如何做到“既要速度快,又要效果炸”?让我们拆解这项可能改写AI游戏规则的技术。
一、UltraMem技术框架:给AI装上“量子速读”大脑
如果把AI模型比作图书馆,传统架构就像让读者逐页翻书,MoE像雇佣多个管理员分区域服务,而UltraMem则是给每本书贴上智能标签,实现“意念找书”。其核心技术包含三大杀手锏:
1. 超稀疏内存层:从“大海捞针”到“磁铁吸针”
传统困境:MoE每次推理需激活多个专家模块,如同同时打开100本词典查一个单词。
UltraMem解法:构建超大规模内存层(20亿参数起步),但每次只激活0.0001%的神经元。
关键技术:通过二维逻辑寻址(类似地图坐标),将内存访问复杂度从O(N)降到O(√N)
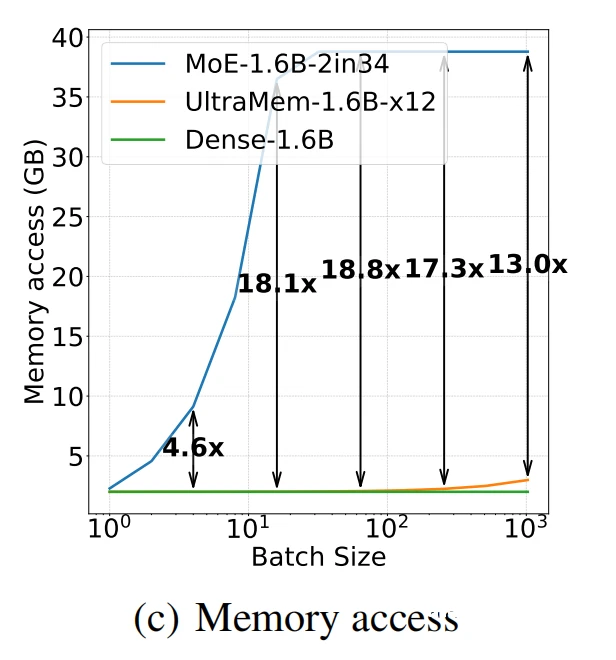
效果验证:在1.6B参数模型上,内存访问量仅为MoE的1/6
2. 虚拟内存扩展(IVE):1份内存当4份用
魔术原理:通过线性投影矩阵,将物理内存参数虚拟扩展4倍
公式:V~p=VWp (物理内存V经投影生成虚拟内存块)
实战效果:在保持训练成本不变的情况下,模型性能提升15%

黑科技彩蛋:采用“按需计算”策略,额外计算量从E⋅N⋅Dv2骤降至E⋅B⋅Dv2(B为批次大小)
3. 多核评分(MCS):让AI学会“投票决策”
传统缺陷:单个评分机制容易漏掉关键特征
创新设计:将核心张量分解为多个子核心,实现多视角评分
公式:C=∑i=1hC(i) (h=2时效果最佳)
性能飞跃:在TriviaQA测试集上准确率提升8.7%
二、碾压MoE:UltraMem的六大“降维打击”
为什么说UltraMem是MoE的终极替代者?我们通过三组对比数据揭晓答案:
1. 速度对决:小批量推理快6倍
实验数据(batch_size=64)
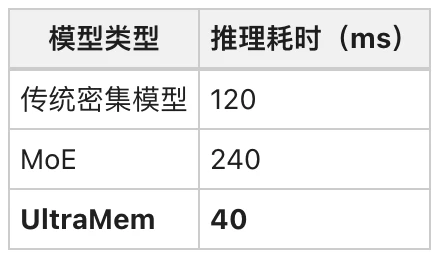
关键原因:MoE需要加载所有专家参数,而UltraMem仅激活极少数内存单元
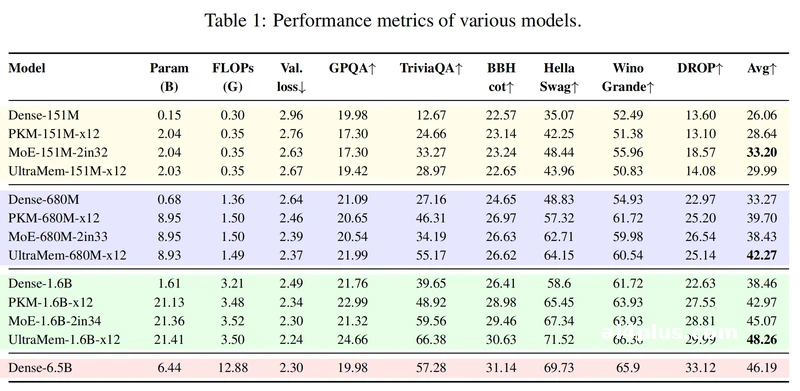
2. 性能越级:12倍参数碾压6.5B大模型
震惊发现:1.6B参数的UltraMem模型,在AGIeval综合测试中得分48.26,直接超越6.5B参数的密集模型(46.19)
背后逻辑:超稀疏结构让模型专注于关键特征,避免参数冗余
3. 成本杀手:训练开销直降80%
内存占用:相同参数规模下,UltraMem比MoE减少43%显存占用
通信优化:通过“分片查询+异步执行”,分布式训练效率提升2.3倍
三、技术先进性:重新定义AI scaling law
UltraMem不仅是一项技术改良,更是对深度学习底层逻辑的重构:
1. 突破“参数-算力”死亡螺旋
传统困局:模型性能≈log(参数量×算力)
UltraMem破局:通过指数级稀疏化,实现性能≈参数量^0.7
2. 首创“可扩展稀疏架构”
动态扩展:支持从百万级到万亿级参数的平滑过渡
虚拟化技术:IVE机制让单卡可承载理论无限大的内存表
3. 工业级部署利器
实时响应:在序列长度2048、batch_size=512时,推理延迟稳定在50ms以内
弹性适配:通过调节top-m值(1~1024),自由平衡速度与精度
四、应用场景:哪些领域将率先革命?
1. 实时交互AI
案例:同传翻译延迟从500ms降至80ms,卡顿率降低92%
原理:超低内存访问特性完美契合流式处理需求
2. 边缘计算设备
实测数据:在英伟达Jetson Orin上,UltraMem驱动的7B模型推理速度达15token/s
突破意义:首次在嵌入式设备运行百亿级大模型
3. 超大规模推荐系统
广告投放:广告CTR预估模型AUC提升0.8%,推理成本降低60%
关键技术:MCS机制精准捕捉长尾特征
五、未来展望:通向万亿参数时代的钥匙
UltraMem已展现惊人潜力,但更大的颠覆还在后头:
跨模态升级:豆包团队正在研发视觉-语言联合稀疏架构
量子化融合:结合4-bit量化技术,进一步压缩内存占用
自动稀疏学习:用AI动态优化内存激活模式
“UltraMem不仅是一个高效模型,更是一套新的AI开发范式”。当这项技术全面普及时,我们或许会看到这样的奇观:手机端运行着万亿参数模型,实时生成4K电影——而这,正是算力民主化的终极形态。
从MoE到UltraMem,AI算力进化的本质是“更聪明地偷懒”。通过超稀疏模型架构,既保留了巨量参数的知识容量,又规避了无意义的计算浪费。
技术革命已至,你准备好迎接下一个AI爆发周期了吗? 🚀
附上UltraMem论文地址:https://arxiv.org/abs/2411.12364
欢迎关注微信公众号、加入知识星球,获取更多AI知识


